When LLMs Learn to Remember — Part 3: How OpenClaw Turns LLMs into an Operating System
OpenClaw treats AI as an infrastructure problem. This deep dive covers its 3-tier memory architecture, MemOS, hybrid search, automatic memory flush, and what it means for the future of AI assistants.
In Part 1, we established that LLMs are completely stateless. In Part 2, we built a memory system from scratch — CRUD operations, post-conversation sweeps, and context trees.
Now let's look at how a real production system does it. OpenClaw is an open-source project that treats AI not as a chatbot, but as an operating system problem. And its memory layer is where the most interesting engineering happens.
What Is OpenClaw?
Most AI tools wrap a model in a chat interface and call it a day. OpenClaw takes a fundamentally different approach:
The LLM provides intelligence. OpenClaw provides the operating system.
It's a hub-and-spoke architecture centered on a Gateway (the control plane) with an Agent Runtime that handles the full AI loop:
┌──────────────────────────────────────────────────┐
│ OpenClaw Gateway │
│ (Control Plane) │
│ │
│ ┌───────────┐ ┌──────────┐ ┌───────────────┐ │
│ │ Session │ │ Memory │ │ Tool │ │
│ │ Manager │ │ System │ │ Sandbox │ │
│ └───────────┘ └──────────┘ └───────────────┘ │
│ ┌───────────┐ ┌──────────┐ ┌───────────────┐ │
│ │ Access │ │ Message │ │ Context │ │
│ │ Control │ │ Router │ │ Engine │ │
│ └───────────┘ └──────────┘ └───────────────┘ │
└──────────────────────────────────────────────────┘
│
┌──────────┴──────────┐
│ Agent Runtime │
│ │
│ 1. Assemble context │
│ 2. Invoke model │
│ 3. Execute tools │
│ 4. Persist state │
└─────────────────────┘
This isn't just a memory system — it's session management, tool sandboxing, access control, and orchestration. The memory system is one component, but it's the most innovative one.
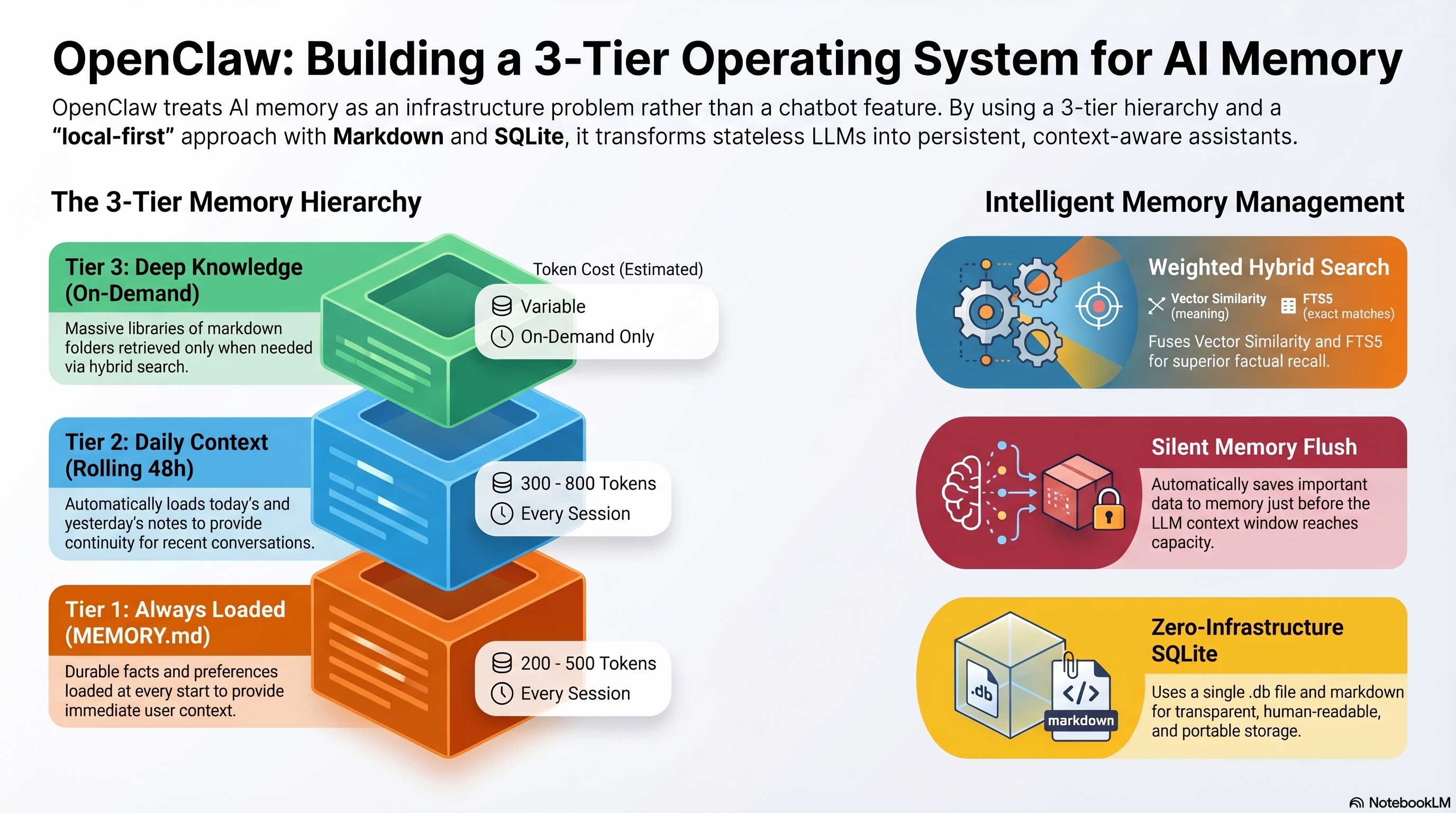
The 3-Tier Memory Architecture
OpenClaw organizes memory into three tiers based on how frequently information is needed:
Tier 1: Always Loaded — MEMORY.md
A single markdown file containing durable facts, preferences, and decisions. This loads at the start of every conversation.
# Memory
## User
- Senior software engineer, based in Switzerland
- Prefers Docker for all backends
- Uses FastAPI, not Flask
## Active Projects
- project-alpha: internal tool (in production)
- blog: Software engineering blog (active)
## Key Decisions
- Prefer stable frameworks over trendy ones
- Containerized deployments across environments
Cost: ~200-500 tokens per conversation. Always worth it.
This is the equivalent of what you'd tell a new colleague on their first day. It never changes conversation-to-conversation, only evolves slowly over weeks.
Tier 2: Daily Context — memory/YYYY-MM-DD.md
Daily note files with running context and observations. Today's and yesterday's files load automatically.
# 2026-04-07
## Morning
- Started OpenClaw research for blog series
- Published Part 1 and Part 2 of memory series
## Decisions
- Split memory blog into 3 parts (was getting too long)
- Series title: "When LLMs Learn to Remember"
## Blockers
- OpenRouter API key not available locally, must SSH to server
Why two days? Most follow-up conversations happen within 24-48 hours. Loading yesterday gives continuity without loading your entire history.
Cost: ~300-800 tokens for two daily files. Automatic and low-overhead.
Tier 3: Deep Knowledge — Structured Folders
Organized by topic, searched on demand via hybrid retrieval:
memory/
├── people/
│ ├── client_mueller.md
│ └── team_sarah.md
├── projects/
│ ├── project-alpha.md
│ └── blog.md
├── topics/
│ ├── docker_deployment.md
│ └── ai_memory_systems.md
└── decisions/
├── 2026-03-architecture.md
└── 2026-04-consulting.md
Not loaded by default. Only pulled when a conversation needs it, via search.
Cost: Variable — only pay for what you retrieve.
How the Tiers Work Together
New conversation starts
│
▼
┌─ Tier 1: Load MEMORY.md (always) ──────────── ~400 tokens
│
├─ Tier 2: Load today.md + yesterday.md ──────── ~600 tokens
│
├─ Read user's first message
│ │
│ ▼
│ "How's the project-alpha deploy going?"
│ │
│ ▼
└─ Tier 3: Search → load projects/project-alpha.md ─ ~300 tokens
Total context: ~1,300 tokens (instead of loading everything: ~15,000+)
The Hybrid Search Engine
When OpenClaw searches Tier 3, it doesn't just use vector similarity or keyword matching. It uses both, fused together.
The Problem with Vector-Only Search
Vector search (embeddings + cosine similarity) is great for fuzzy queries but terrible for exact matches:
- Query: "What port does Redis run on?"
- Vector search might return: documents about caching, database configuration, port management — all semantically related but none containing the exact answer.
The Problem with Keyword-Only Search
Full-text search is great for exact terms but terrible for meaning:
- Query: "How do I containerize the backend?"
- FTS might miss: a document that says "wrap the API in Docker" because it doesn't contain "containerize."
OpenClaw's Solution: Weighted Score Fusion
Query: "Redis port configuration"
│
┌─────────┴─────────┐
▼ ▼
Vector Search FTS5 Search
(sqlite-vec) (SQLite FTS)
│ │
▼ ▼
cosine_score = 0.82 fts_score = 0.91
│ │
└─────────┬─────────┘
▼
final_score = (0.4 × cosine) + (0.6 × fts)
= (0.4 × 0.82) + (0.6 × 0.91)
= 0.874
The weighting is configurable, but the default favors FTS slightly — because for AI assistant memory, exact factual recall matters more than fuzzy semantic similarity.
All in SQLite
Here's the clever part: both the vector index and the full-text index live in SQLite. No Postgres, no Chroma, no Qdrant. Just a single .db file.
- sqlite-vec extension for vector operations
- FTS5 virtual tables for full-text search
- Single file, zero infrastructure, fully portable
This means your entire memory system is one SQLite file and a folder of markdown files. Back it up by copying two things.
Automatic Memory Flush
This is OpenClaw's most clever feature and it solves a problem most people don't even realize exists.
The Problem
LLMs have context window limits. When a conversation gets long, OpenClaw must compact older messages — summarize and drop them to make room. But those older messages might contain important information that hasn't been saved to memory yet.
The Solution
Before compacting, OpenClaw triggers a silent agentic turn — an invisible prompt to the model:
[System]: Context compaction imminent. Before older messages
are removed, review the conversation and write any important
information to memory that hasn't been persisted yet.
The model gets one last chance to save anything important before the context is compressed. The user never sees this happen.
Conversation grows...
│
Context window 80% full
│
▼
┌─ Silent memory flush ──────────────────┐
│ Model reviews conversation │
│ Writes unsaved knowledge to memory/ │
│ Updates MEMORY.md if needed │
└─────────────────────────────────────────┘
│
Context compaction runs
│
Older messages summarized/dropped
│
Conversation continues (memory is safe)
This is essentially an automatic post-conversation sweep that runs during the conversation, triggered by a resource constraint. Elegant engineering.
MemOS: The Memory Plugin Layer
MemOS is a separate project that plugs into OpenClaw as a dedicated memory operating system. Think of it as PostgreSQL to OpenClaw's application server — a specialized engine for one job.
What MemOS Adds
| Feature | OpenClaw Native | With MemOS |
|---|---|---|
| Storage | Markdown files + SQLite | Graph-based structured storage |
| Modalities | Text only | Text, images, tool traces, personas |
| Multi-agent | Single agent memory | Isolated memory per agent with sharing |
| Knowledge bases | One flat set | Composable "memory cubes" |
| Memory API | File read/write | Unified CRUD with async ops |
Memory Cubes
This is MemOS's most interesting concept. A "memory cube" is an isolated knowledge base that can be composed with others:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Personal │ │ Project A │ │ Company │
│ Preferences │ │ Context │ │ Knowledge │
│ Cube │ │ Cube │ │ Cube │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└────────────────┴────────────────┘
│
Agent Session Context
(composed from 3 cubes)
Different agents can share the Company cube while having their own Personal cube. A code review agent doesn't need your calendar preferences; a scheduling agent doesn't need your code style preferences.
Multi-Agent Isolation
Each agent gets its own agent_id automatically injected into memory operations. Agent A's memories are invisible to Agent B unless explicitly shared via a common cube.
# Agent A (coding assistant)
search_memory(agent_id="coder", query="deployment process")
# → Returns only coding-related memories
# Agent B (scheduler)
search_memory(agent_id="scheduler", query="meeting preferences")
# → Returns only scheduling-related memories
# Shared knowledge base
search_memory(cube="company", query="team structure")
# → Both agents can access this
MemSearch: The Extracted Library
The team at Zilliz (creators of Milvus vector database) thought OpenClaw's memory approach was so good that they extracted it into a standalone library called memsearch.
It's a Markdown-first memory system for any AI agent:
- Same hybrid search (vectors + FTS)
- Same SQLite-based storage
- Works with any LLM, not just OpenClaw
- Drop-in library, not a framework
This means you can use OpenClaw's memory architecture in your own projects without adopting the full OpenClaw ecosystem.
What OpenClaw Gets Right
1. Files Are the Source of Truth
Everything is in markdown files on disk. Not in a database you can't read, not in embeddings you can't inspect. You can open any memory file in a text editor, read it, edit it, delete it.
This is a fundamental design choice: human-readable memory that the AI happens to use, not AI memory that humans can barely access.
2. Temporal Awareness Built In
The daily files (YYYY-MM-DD.md) with automatic loading of today + yesterday solve the "when did I decide this?" problem that flat memory systems struggle with.
3. Graceful Degradation
If the vector search breaks, FTS still works. If FTS breaks, Tier 1 and Tier 2 still load. If everything breaks, the AI still works — just without memory, like any other LLM.
4. Zero External Infrastructure
SQLite + markdown files. No Redis, no Postgres, no cloud vector database. This makes it portable, testable, and debuggable.
What's Still Missing
No Standard Memory Schema
Every OpenClaw user structures their MEMORY.md differently. There's no convention for what goes where, what format to use, or how to handle conflicts. Compare this to databases where we have normal forms, migration tools, and schema management.
No Memory Versioning
When a memory is updated, the old version is gone. There's no changelog, no way to see what you knew last month versus today. Git can help (version the memory folder), but it's not built in.
No Cross-Device Sync (Without Cloud)
The local-first approach is great for privacy but means your memory doesn't follow you between machines without manually syncing. MemOS Cloud addresses this, but then you lose the "zero infrastructure" benefit.
No Memory Governance
Who decides what gets remembered? The model does, and models make mistakes. There's no approval workflow, no "review pending memories before they're committed," no way to set policies like "never remember financial information."
How This Maps to What We Built
In Part 2, we designed a memory system from first principles. Here's how it maps to OpenClaw:
| Our Concept | OpenClaw Equivalent |
|---|---|
| Memory CRUD operations | File read/write + MemOS API |
| Post-conversation sweep | Automatic memory flush (before compaction) |
| Context tree hierarchy | 3-tier architecture (always/daily/deep) |
| Decay and archival | Not built in (manual cleanup) |
| Conflict resolution | Not built in (last-write-wins) |
| Hybrid retrieval | sqlite-vec + FTS5 weighted fusion |
We independently arrived at many of the same conclusions. The industry is converging on this pattern: markdown files + smart retrieval + LLM self-curation.
The Takeaway
OpenClaw shows us where AI assistants are heading. Not smarter models — smarter infrastructure around the models.
The model is the brain. But a brain without memory, without context, without a sense of time, is just a very fast pattern matcher.
The operating system layer — memory management, session handling, tool execution, context assembly — is what turns a stateless function into something that feels like an assistant that actually knows you.
And the best part? The core ideas are simple enough to implement yourself:
- Tier 1: A single file with your core context, always loaded
- Tier 2: Daily notes, auto-load recent ones
- Tier 3: Topic folders, searched when needed
- Hybrid search: Combine keywords and vectors
- Auto-flush: Save memory before context gets dropped
You don't need OpenClaw to do this. But understanding how it works helps you build something that works just as well for your specific needs.
Series Summary
This three-part series covered the full journey:
- Part 1: LLMs Don't Remember Anything — The fundamental problem: LLMs are stateless, all memory is an illusion built by the application layer
- Part 2: Building a Memory System — The hands-on solution: Memory CRUD, post-conversation sweeps, context trees, and what's still unsolved
- Part 3: How OpenClaw Does It (this post) — The production reality: 3-tier architecture, hybrid search, automatic memory flush, and MemOS
The pattern is clear: the future of AI isn't just better models — it's better memory.
Find me on LinkedIn for more practical AI engineering content. All three posts in this series are available on software-engineer-blog.com.